The APEX Framework: Agentic Production Execution
The complete APEX Framework — three areas, nine domains, ten principles, five metrics. Strategic → Execution → Reflection. A production-grade operating model for teams where humans design and verify while agents execute and iterate.

A few months ago I found myself running ten agents across three different projects. Code agents, content agents, research agents. They were producing work. Some of it was good. Some of it was quietly terrible, and I didn't catch it until it had already shipped downstream. The problem wasn't the agents. The problem was me. I had no system for how humans and agents should work together. No structure for who decides what, when agents should iterate on their own, and when a human needs to step in.
Anthropic recently published their findings on harness design for long-running applications, and the results are striking. By separating the agent doing the work from the agent evaluating it, and by designing structured criteria for that evaluation, they dramatically improved output quality across both subjective design tasks and verifiable code. A planner decomposes the work. A generator executes. An evaluator grades and critiques. The generator iterates against that feedback until quality thresholds are met.
This is a proven inner loop. And it confirms something that anyone running agents in production has already felt: harness design matters more than model selection, and agent-to-agent review is a stronger quality lever than self-evaluation.
Anthropic built a fantastic engine. APEX is an attempt to describe the vehicle around it — the steering, the instruments, the navigation. Their work answers how to make agents produce better output. The questions that remain are organizational: who defines the grading criteria when it's a team of five? How do those criteria improve over time? Who owns which part of the system? How do you measure whether the whole operation is getting better, not just one individual run? That's where most writing about AI agents stops: at the individual playbook, and often with a purely engineering lens — as if harness design and prompt optimization are the whole picture. They're essential, but they're the foundation, not the building. When you have three, five, ten people who all need to interact with an agentic system, the individual playbook breaks down. You need organizational structure: who owns what, how quality is governed, how the system evolves.
That's the gap APEX fills. Anthropic proved the inner loop. APEX provides the outer one — the organizational scaffolding that scales those insights from a single engineer's workflow to a team-wide operating model.
What matters most: your existing experts don't become obsolete in an agentic system. They become more valuable. A tech lead who spent ten years understanding architecture doesn't get replaced. They own Platform and Orchestration Design. A product manager who knows the market and the users doesn't get sidelined. They own Business Context and Spec Engineering. A QA lead who understands what quality means in your domain doesn't disappear. They own QA Strategic and QA Operational. APEX gives every expert a clear, named domain where their experience translates directly into system design. The job changes. The value doesn't. It concentrates.
This is the complete reference.
Index
- Chapter 1: Introduction
- Chapter 2: The APEX Cycle
- Chapter 3: The Strategic Phase
- Chapter 4: The Execution Phase
- Chapter 5: The Reflection Phase
- Chapter 6: The Ten Principles
- Chapter 7: APEX Metrics
- Chapter 8: Framework Pluggability
- Chapter 9: Anti-Patterns
- Chapter 10: Getting Started
Chapter 1: Introduction
APEX exists because individual AI playbooks don't scale to teams. This chapter defines the problem, the framework's scope, and the thinking behind it.
The problem APEX solves
The gap between "one person using agents well" and "a team of humans running agentic production" is where most organizations stall. Individual productivity with agents is increasingly well understood. Organizational productivity with agents is not. You need structure for who owns what, how quality is governed, how the system evolves. That structure is what APEX provides.
What APEX is (and is not)
APEX stands for Agentic Production Execution. It is a framework for optimizing how agents execute production work — by wrapping that execution in strategic phases where humans design the system, verification gates where humans validate output, and continuous calibration where the system evolves based on data. It is not a guide for how an individual should prompt or configure an agent. It is not a replacement for your existing methodology. It is not prescriptive about tooling. It is organizational scaffolding that makes agentic execution reliable, measurable, and improvable at scale.
The philosophy behind it comes from running agentic teams daily. Agents are team members, not tools. They need roles, responsibilities, memory, and communication protocols. Humans design and verify while agents execute and iterate. Output quality is always a function of input quality. Trust is earned through architecture, not faith. The harness determines the ceiling. And the conviction I keep coming back to: outsource execution, keep strategy human. The moment you let agents decide what to build rather than how to build it, you've lost the thread.
These convictions shape every part of the framework. They aren't separate from the work. They're the lens through which every domain, every principle, and every decision is made.
I mapped the nine domains across three areas in The Anatomy of a Level 3 Agent. That gave me a vocabulary for what autonomous systems need. But domains don't tell you who owns quality, how work flows from idea to verified deliverable, or what happens when the system itself needs to change. APEX answers those questions. It organizes that work into three areas and nine domains, each with clear ownership, clear boundaries, and clear artifacts. And it defines a cycle that keeps the whole system evolving.
Chapter 2: The APEX Cycle
The heartbeat of the framework. Strategic → Execution → Reflection. This is how human expertise and agent capability stay connected across every work cycle.

Everything in APEX revolves around three phases that repeat continuously: Strategic, Execution, and Reflection. These form the macro rhythm of any agentic operation. Each phase has a distinct purpose, a distinct actor in the lead, and a distinct failure mode when neglected.
Strategic (Human-First)
Strategic is where humans do all the thinking that agents will later act on. Every adjustment to the system happens here. All nine domains live in Strategic because every domain represents a design decision that humans own: choosing the harness, writing the specs, configuring the agents, defining quality gates, setting permissions.
This is the phase where the tech lead designs orchestration flows. Where the product manager writes the spec. Where the content strategist documents editorial guidelines. Where the security owner configures permissions. Where QA defines what "done" means.
Strategic is where most agentic projects either succeed or fail, and most people want to skip past it because it feels like overhead. It is not overhead. It is the work. Agents can only execute within the boundaries humans draw. The velocity gain in this phase is modest — roughly 2-3x compared to traditional work, but that acceleration is real. Every artifact produced in Strategic benefits from AI assistance: Claude or Gemini for drafting personas, researching competitive landscapes, and generating spec templates. Dedicated agents configured as Operational Tooling can automate context generation, brief scaffolding, and documentation builds. The human role is curation and sign-off, not blank-page creation. The real acceleration comes in the next phase. If you draw those boundaries carelessly, agents will produce careless output, and you'll blame the agents instead of the system design.
The artifacts produced in Strategic are concrete: harness decision records, spec documents, agent identity files, workflow maps, permission maps, quality criteria, business context documentation. Every one of these feeds directly into what agents do during Execution. The richer and more precise these artifacts are, the less agents need to infer. And inference is where drift happens.
Execution (Agent-First)
Once Strategic is complete, agents take over. They execute against the specs, the configurations, the quality gates that humans defined. This is the phase that runs fast — 10-20x velocity compared to traditional human execution. Agent-to-agent review loops, iteration cycles, automated quality checks. The inner machinery of production.
The human role in Execution is exactly one thing: verification. Not specifying. Not configuring. Not redesigning. Verifying output. When work completes the agent-to-agent review cycles and meets the criteria defined in QA Operational, it surfaces for human verification against the criteria defined in QA Strategic.
This is where the speed advantage lives. Agents iterate in seconds. A review agent flags issues, the executing agent fixes them, another review pass runs. By the time work reaches a human, the mechanical problems are resolved. The human focuses on whether the output actually moves the business forward, whether it captures the intent that was specified in Strategic.
The discipline required here is restraint. If you find yourself constantly stepping into agent loops to clarify, redirect, or fix things during Execution, the problem is not the agents. The problem is in your Strategic configuration. Every intervention during Execution is a signal that something upstream needs better design.
Each phase has different bottlenecks, costs, and value outputs. In the Strategic Phase, the bottlenecks are humans, time, and the quality of ideas. The cost is measured in hours of expert attention. The value produced is system design that compounds across every future cycle. In the Execution Phase, the bottlenecks are agent capacity and quality gate throughput. The cost is measured in tokens and compute. The value is production output at scale. In the Reflection Phase, the bottleneck is willingness to act on what the data shows. The cost is time. The value is learning — the only thing that makes the next cycle better than the last one.
Reflection
After a work cycle completes, the system pauses to learn. This phase runs at roughly 1-2x velocity compared to traditional retrospectives — agents pre-compile their metrics and surface patterns automatically, so humans spend time deciding rather than gathering data.
The Reflection Phase follows three steps: Evaluate the output against original intent, Reflect on what the data reveals about system performance, and Calibrate by implementing changes to the Strategic configuration.
Reflection is where the system evolves. Maybe specs in a particular domain were consistently too vague, causing excessive iterations. That's a Strategic problem to fix next cycle. Maybe an agent's identity file was missing context that led to drift. That's Agent Design. Maybe a routing rule sent work to the wrong agent. That's Orchestration Design. The data tells you where to invest.
The output of Reflection feeds directly back into Strategic. The cycle restarts, but now the system is better than it was. Strategic designs improve because they're informed by real execution data. Agents perform better because their configurations evolved. Quality gates sharpen because you know which checks caught real problems and which were noise.
This is what separates APEX from a static pipeline. A pipeline runs the same way forever. APEX evolves.
The Cycle in Practice
Strategic → Execution → Reflection → Strategic → Execution → Reflection. The cadence depends on your operation. It might be daily for a content team. Weekly for a product team. Per-project for a consulting engagement. The rhythm matters less than the commitment to running all three phases every cycle.
When delivery pressure is high, Reflection is the first thing that gets cut. They ship, move on, start the next sprint. The result is predictable: the same problems repeat. Iteration depth stays flat. First-pass acceptance doesn't improve. The agents aren't getting smarter because nobody is feeding execution data back into the system.
The organizations that run all three phases consistently are the ones where agents actually get better over time. That compounding effect is the entire point.
The Full Cycle
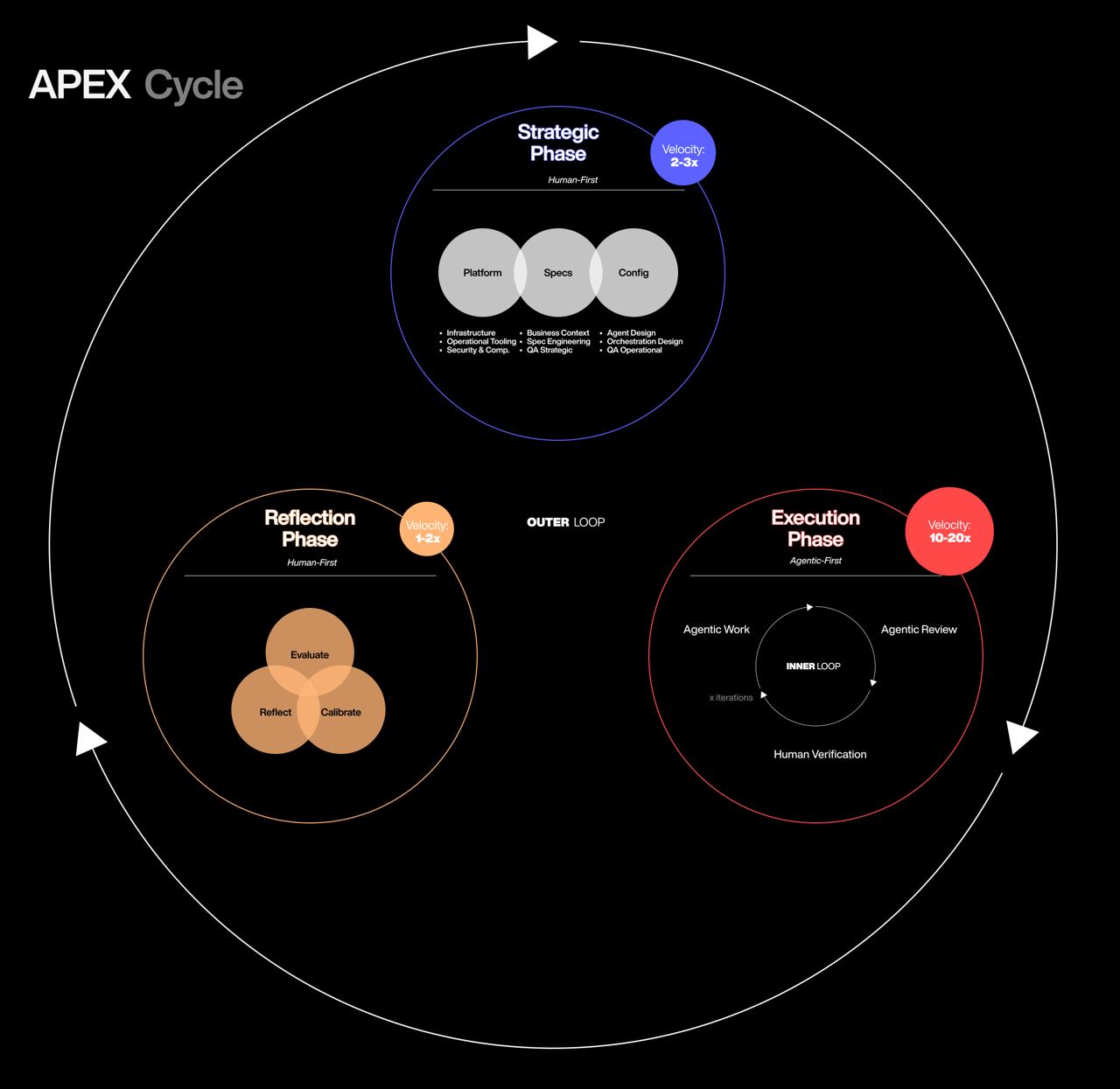
The diagram above captures the complete APEX Cycle. The Strategy Phase sits at the top, where humans design the system across three areas: Platform, Specification, and Config. Work flows into the Execution Phase, where the inner loop runs at 10-20x velocity — agents work, agents review, humans verify. From there, work moves to the Reflection Phase, where the team evaluates output, reflects on system performance, and calibrates. The calibration feeds back into Strategy, and the cycle repeats with an evolved system.
Three things to notice. First, the velocity differences between phases are significant. Strategy runs at 2-3x because AI assists but humans drive every decision. Execution runs at 10-20x because agents handle the iteration loops. Reflection runs at 1-2x because it requires human judgment on what to change. The total cycle is dramatically faster than traditional delivery, but the speed is concentrated in Execution — not spread evenly.
Second, the inner loop during Execution is where most of the actual production happens. Agentic Work produces output. Agentic Review validates it against QA Operational criteria. The loop iterates until the quality gate passes. Only then does work surface for Human Verification against QA Strategic criteria. Humans see pre-validated work, not first drafts.
Third, the Reflection Phase is not optional. Without it, the system runs on the same configuration cycle after cycle, regardless of what the data shows. Evaluate, Reflect, Calibrate — three steps that close the outer loop and feed improvements back into Strategy. Skip them and APEX degrades into a static pipeline.
Chapter 3: The Strategic Phase
APEX organizes Strategic work into three areas containing nine domains. Platform is the foundation everything runs on. Spec is what humans specify and measure. Config is what humans configure for agent execution. Each area has clear ownership, clear artifacts, and clear boundaries.

The three-area structure reflects how work actually flows. Platform is the ground you build on. The Spec Area is what humans decide should happen and how they'll measure whether it did. The Config Area is how agents are configured to execute that work autonomously. QA appears in both Spec and Config, deliberately. Strategic QA lives in Spec because humans define what "good" means. Operational QA lives in Config because agents need quality checks within their execution cycles. Separating the two prevents the common failure where nobody owns quality at the system level because "the agents check their own work."
The nine domains from The Anatomy of a Level 3 Agent map into these areas. Harness selection, compute, CI/CD, tool integrations, and code execution belong to Infrastructure. Dashboards, metrics pipelines, and context-generation tools belong to Operational Tooling. Permissions and audit trails belong to Security and Compliance. Business documentation belongs to Business Context. Requirements and specs belong to Spec Engineering. Quality definitions belong to QA Strategic. Agent identities, skills, and memory belong to Agent Design. Routing and delegation belong to Orchestration Design. Agent-level quality checks belong to QA Operational. Each capability has a home. None falls through the cracks.
Platform Area
Platform is the foundation. Everything else runs on top of it. You set it up, you maintain it, and if it breaks, nothing above it works. Three domains live here.
Infrastructure owns the runtime, the compute, and everything that keeps the system alive. This is where you make the most consequential decision in the entire framework: choosing your harness.
The harness — the runtime that sits between the language model and everything else — determines what orchestration patterns are possible, what deployment models you can rely on, and what security boundaries you can enforce. Pick the wrong harness and you'll spend months working around limitations that were baked in on day one. Document it in a Harness Decision Record.
Six types exist in the current ecosystem, and as a rough guide for where each tends to fit best as of early 2026:
General purpose (Claude Code, Codex CLI, Cursor, Windsurf) — when you need flexibility across varied tasks and a human is available to steer. Software development, research, exploration. The natural starting point for most teams getting into agentic work.
Specialized (Devin, Harvey) — when you need deterministic reliability in a specific domain. Legal review, compliance workflows, financial analysis — anywhere the cost of getting it wrong outweighs the value of flexibility. If your workflow has regulatory requirements or needs auditability, specialized harnesses with structured rails tend to be the safer choice.
Autonomous (OpenClaw, CrewAI) — when agents need to operate without human presence. Monitoring, scheduled workflows, proactive assistants. If the agent needs to wake up at 3 AM, check something, and act on it, you need an autonomous harness.
Hierarchical (AutoGen, ChatDev, MetaGPT) — when the work naturally decomposes into a coordinator delegating to specialists. Large projects with clear sub-tasks that different agents can own independently.
DAG-based (LangGraph, Prefect, Dagster, Flyte) — when the workflow shape is known upfront and you need parallel execution, conditional branching, and full observability of each step. Data pipelines, content production workflows, anything where you want deterministic control over the execution path.
Hybrid — where most mature setups end up. An autonomous harness handles lifecycle and scheduling while specialized or general purpose sub-agents handle specific domains. This is worth planning for even if you start simpler.
These categories are fluid — the boundaries are blurring as tools evolve. The important thing is making the choice deliberately rather than by default.
Beyond the harness, Infrastructure owns model strategy (which LLMs power which agents, fallback chains when providers hit limits), compute and deployment (cloud or on-premise, CI/CD pipelines), tool integrations, and monitoring. Agent workloads are fundamentally different from web app workloads — they're long-running, stateful, and unpredictable. Monitoring matters more than you'd think: when an agent runs autonomously, you need to know when it's stuck, when it's burning tokens on a loop, when it's producing degraded output. The artifacts are a Harness Decision Record, a Model Strategy, a Tool Registry, and an Infrastructure Config.
Operational Tooling is the visibility and support layer for the entire APEX Cycle. Dashboards, metrics pipelines, context-generation tools, agent activity monitors — everything that helps humans see and steer the system across all three phases.
In the Strategic Phase, Operational Tooling means context generators and documentation builders that help humans produce better specifications faster. In the Execution Phase, it means real-time dashboards showing what agents are doing, where they're stuck, and how much they're costing. In the Reflection Phase, it means metrics visualizations that make APEX Metrics actionable — first-pass acceptance rates over time, iteration depth per deliverable type, calibration impact across cycles.
Without this domain, Reflection degrades into guesswork. You can define all the metrics you want in QA Strategic, but if there's no tooling to surface them, data-driven calibration doesn't happen. Operational Tooling is the bridge between measuring and acting.
The artifacts are a Tooling Registry (what exists and who maintains it), dashboard configurations, and context-generation templates. This domain maps naturally to a developer or DevOps engineer who builds and maintains the tooling that everyone else relies on.
Security and Compliance owns who can access what, what data flows where, and what regulatory constraints apply. Permissions, audit trails, data access boundaries, guardrails. In regulated industries, this domain often becomes the constraining factor across every other domain. A content agent doesn't need production database credentials. A code agent doesn't need access to financial records. The artifacts are a Permission Map and a Compliance Registry.
The three Platform domains share a characteristic: invisible when working well, catastrophic when neglected. An unstable runtime, missing tooling, or a permission gap will undo weeks of good work in the areas above.
Spec Area
The Spec Area is where human expertise translates into specifications that agents can work from, and where humans measure whether the output matched the intent. This is where you define what should happen and how you'll know if it did. Three domains live here.
Business Context is where most of the strategic investment goes. This is the "why" and the "for whom." Business case, brand understanding, personas, competitive landscape, vision. You collect client briefs, project briefs, brand guidelines, design systems, and compliance requirements. In a content operation, this means brand positioning and audience strategy. In a financial operation, risk parameters and regulatory constraints.
Business Context owns everything an agent needs to know to produce domain-appropriate output. It works best as a phased build. Foundation first: business case, brand, competitive context. Then users and experience: personas, journey maps, accessibility requirements. Then technical and domain-specific context that accumulates as the project matures. Each phase layers on the previous one.
A common mistake is treating Business Context as a one-time exercise. Write the docs, hand them to agents, move on. That's the Set-and-Forget anti-pattern applied to documentation. Business Context is a living collection. As agents execute and you learn from Reflections, the artifacts evolve. The phased build never really ends. It shifts from initial creation to iterative refinement.
Spec Engineering is the translation layer between strategic thinking and executable work. Product requirements, user stories with acceptance criteria, MVP scope, content guidelines. The PRD becomes the single source of truth. User stories with clear acceptance criteria are what agents decompose into tasks.
Spec Engineering owns human intent. It does not own agent capabilities. A spec document describes what should be produced and the criteria for success. How agents are configured to produce it belongs in the Config Area. When Spec Engineering starts including agent instructions, you've blurred a boundary that causes problems downstream. Keep them separate.
QA Strategic is the measurement and evaluation layer. Measurement plans, calibration specs, human evaluation criteria, definition of how output quality is assessed. This domain answers: how do we know the output is good enough?
QA Strategic owns the definition of quality at the system level. What does "done" mean for each deliverable type? What data feeds into Reflections? The artifacts are Review Criteria documents and Reflection Report templates. The primary handshake is with Spec Engineering on input and with QA Operational in the Config Area on execution.
Config Area
The Config Area is where humans configure how agents behave, collaborate, and check each other's work. Agents then run autonomously within this configuration during Execution. Three domains live here.
Agent Design is where agents get their identities. Agent identity files, behavior configuration, skills, instructions, state management, memory architecture. This is about performance in the truest sense: how well does each agent consume context and produce the right output? If an agent consistently misinterprets a spec, that's an Agent Design problem. If output quality drifts because an agent's behavior wasn't calibrated to the business context, that's an Agent Design problem.
The artifacts are an Agent Roster and Agent Identity Files. Each identity file defines the agent's role, its instructions, what skills it has access to, how it manages state between tasks, and what memory it retains across sessions. The richer the identity file, the less the agent needs to infer, and inference is where drift happens.
Orchestration Design owns the flows between agents. Routing rules, delegation chains, handoff protocols, done-criteria, workflow maps. When a task arrives, which agent handles it? When that agent finishes, where does the work go next?
A simple workflow might be one agent executing and another reviewing. A complex workflow might involve a research agent feeding a writing agent, a review agent checking the output, and a routing agent deciding whether to iterate or escalate. The artifacts are Workflow Maps and Routing Rules. Orchestration Design does not own what agents do (that's Agent Design) or what they're working toward (that's Spec Engineering). It owns the traffic between them.
QA Operational is the quality layer inside the execution loop. Agent-to-agent review criteria, quality gates within iteration cycles, automated checks per iteration. While QA Strategic defines what "good" means at the system level, QA Operational translates those definitions into checks that run every time an agent produces output.
The distinction between the two QA domains is important. QA Strategic is owned by humans who define quality. QA Operational is configured by humans but executed by agents. A review agent checking whether a code change passes tests, whether an article matches the brand voice guidelines, whether a financial analysis uses the correct data sources: that's QA Operational. The human who designed those checks operates in QA Strategic. The agent executing them operates in QA Operational.
This two-level structure also addresses a well-documented failure mode: agents are unreliable judges of their own work. They skew positive, praising output that a human would call mediocre. By separating who defines quality (humans, in QA Strategic) from who enforces it (a dedicated review agent, in QA Operational), and never letting the generator evaluate itself, you get reliable quality enforcement at scale. You design quality once, agents enforce it continuously.
How the Areas Connect
All nine domains live in Strategic. That's where humans design, configure, specify, and adjust every part of the system. During Execution, agents operate within those configurations. During Reflection, execution data reveals which domains need attention.
The three areas have different change frequencies. Platform changes are the least frequent but most impactful. A harness switch affects everything above it. Spec Area changes happen when the business changes: new personas, revised strategy, updated requirements. Config Area changes happen when calibration reveals better agent configuration: adjusted routing, refined identity files, tighter quality checks.
A tech lead who used to review every pull request now defines quality criteria in QA Strategic and review rules in QA Operational that agents follow autonomously. A product manager who used to write individual user stories now writes specs in Spec Engineering that agents decompose and execute. A content strategist who used to edit every article now defines editorial guidelines in Spec Engineering that review agents enforce through QA Operational. And a developer who used to write code all day can now serve as the human quality gate during Execution — reviewing the code that agents produce, verifying it against the patterns they know intimately, and catching the architectural drift that no automated check will flag. Their code expertise doesn't go away. It becomes the verification lens. The expertise doesn't disappear. It moves up one level of abstraction, from doing to orchestrating.
For some experienced leaders this is second nature. They already think in systems. For others it takes repetition and practice. Both are fine. The important part is recognizing that the translation from domain expertise to systems thinking is the core skill APEX asks of humans.
Expert-Domain Mapping
Not everyone needs to own every domain. In fact, that's an anti-pattern. Domain ownership maps to expertise, and the mapping changes as your organization evolves.
How Domains Map to Roles
Domain ownership maps to expertise. The person who understands runtime tradeoffs owns Infrastructure. The person closest to the business problem owns Business Context. The person who thinks in systems and flows owns Orchestration Design. Matching domain to expertise prevents the scenario where someone is technically responsible for a domain they don't understand well enough to configure correctly.
Example 1: Product Development

In a product development team, the domain mapping typically looks like this:
Platform Area. The Tech Director or CTO owns Infrastructure, including the harness decision and model strategy. They evaluate runtime tradeoffs and make the strategic platform decisions. A developer or DevOps engineer owns Operational Tooling: dashboards, metrics pipelines, and context-generation tools. A Security Engineer (or the Tech Lead wearing that hat) owns Security and Compliance: permissions, audit trails, and access controls.
Spec Area. The Product Manager owns Business Context. They're closest to the market, the users, and the business case. Spec Engineering is shared between the Tech Lead, PM, and Design Lead, translating business context into executable specifications, wireframes, and acceptance criteria. QA Strategic is owned by the Tech Director or QA Lead. They define what "done" means at the system level and design the measurement plan.
Config Area. The AI Engineer and Tech Lead co-own Agent Design, configuring agent behavior, skills, memory, and tool access. Orchestration Design falls to the Tech Lead or Scrum Master: workflow maps, routing rules, delegation chains. QA Operational is the QA Lead's domain, translating strategic quality definitions into automated agent-level checks and review criteria.
Example 2: Content Production

Content teams look different. The emphasis shifts from technical architecture to editorial expertise and brand consistency.
Platform Area. Infrastructure still needs a technical owner for the harness decision, but the choice is more about content-specific agent tools (specialized harnesses for editorial workflows) vs general-purpose ones. Operational Tooling focuses on editorial dashboards, content metrics, and brief-generation tools. Security and Compliance focuses on publishing permissions, brand protection, and ensuring agents don't publish unverified content.
Spec Area. Business Context is owned by a Content Manager or Editorial Lead. They understand the audience, the brand voice, the editorial calendar, and the strategic goals. Spec Engineering is where Content Strategists and Copywriters define briefs: topic, angle, tone, SEO requirements, target audience, word count, references. QA Strategic is owned by the Editorial Lead, defining what "publish-ready" means, fact-checking standards, brand voice consistency criteria.
Config Area. Agent Design is configured by whoever understands the content agents, an AI Engineer or technically skilled Content Manager. The writing agent needs different identity, skills, and memory than a code agent. Orchestration Design defines the editorial workflow: research agent → writing agent → review agent → iterate → human verifies. Copywriters and editors contribute by defining the review criteria the agents enforce. QA Operational runs the agent-to-agent review loops: does the draft match the brief? Does the tone match the brand voice? Are sources verified?
The key difference: in content production, the Design Lead role doesn't exist in the same way. Instead, a Content Manager Lead orchestrates the Spec Area, and copywriters and editors operate as domain experts whose editorial judgment shapes both the specs and the quality gates. Their expertise doesn't disappear. It shapes the system.
Small Team vs Large Organization
A single person can own multiple domains, especially in smaller teams. In a two-person operation, one person might own the entire Platform Area plus Agent Design while the other owns the Spec Area domains plus Orchestration Design and QA Operational. In a larger organization, each domain has a dedicated owner or even a dedicated team.
The natural grouping by area helps. A small team might assign one person per area rather than one person per domain. That works fine as long as the boundaries between domains stay clear even when one person crosses them.
The Domain Ownership Matrix is a living document. Review ownership at every Reflection.
Using RACI for Domain Responsibility
For teams that want more granularity than a simple ownership matrix, APEX recommends mapping each domain using RACI: Responsible (does the work), Accountable (owns the result), Consulted (gives input), Informed (needs to know).
A practical example for product development: Infrastructure might have the CTO as accountable, the AI Engineer as responsible, the Tech Lead as consulted, and the PM as informed. Spec Engineering might have the PM as accountable, the Tech Lead and Design Lead as responsible, the Content Strategist as consulted, and the QA Lead as informed. QA Operational might have the QA Lead as accountable, the Tech Lead as responsible, the Agent Design owner as consulted, and the PM as informed.
The value of RACI in APEX is diagnostic. It reveals two problems immediately. First, if one person is Accountable for too many domains, they're overloaded and becoming a bottleneck. Second, if a domain has no clear Accountable, it's orphaned — and orphaned domains produce the blind spots that agents fill with assumptions.
Update the RACI at every Reflection. As the team learns which domains need more attention and which run smoothly, the assignments shift. A domain that needed heavy senior involvement in the first cycle might be delegated to a more junior owner by cycle five. That progression is a sign the system is maturing.
Chapter 4: The Execution Phase
The inner loop where agents do the actual work. Spec → Execute → Review → Iterate → Verify. This is what runs inside the Execution phase of the APEX Cycle.

The Inner Loop
The system is designed. The artifacts are in place across all three areas. Platform is stable. The Spec Area has produced specifications and quality definitions. The Config Area has configured agents and their orchestration. Strategic is complete. Now Execution begins, and agents run within those boundaries.
The core execution loop is straightforward. A human writes a spec. An agent executes against that spec. Another agent reviews the output against criteria defined in QA Operational. Issues are identified and the executing agent iterates. This continues until the spec is met, at which point a human verifies the final output against criteria defined in QA Strategic.
Spec → Execute → Review → Iterate → Verify.
This loop is domain-agnostic. In a product development context, the spec might be a feature brief with acceptance criteria. The executing agent writes code. A review agent checks it against the criteria, runs tests, flags issues. The executing agent fixes them. After two or three iterations, the output meets the spec and goes to human verification. The human never saw the intermediate versions. They see the polished result.
In a content operation, the spec might be an editorial brief with tone guidelines and SEO requirements. The executing agent writes. A review agent checks against the brief, flags tone drift, identifies missing keywords. The executing agent revises. Same loop, different domain.
Agent-to-Agent Review
Principle 4 says all work passes through agent-to-agent review before a human sees it. This is counterintuitive for people used to traditional review flows where a senior person reviews junior work. In APEX, the first line of quality assurance is another agent, configured through QA Operational with criteria defined in QA Strategic.
Agent review is cheap and fast. A review agent checks work against documented criteria in seconds. It catches spec mismatches, style violations, missing sections, logical inconsistencies. By the time a human sees the work, the obvious problems are resolved. The human focuses on whether the work captures the intent that was specified in Strategic.
Anthropic's research on harness design confirms why this separation matters: when agents evaluate their own work, they reliably skew positive — confidently praising mediocre output. Separating generation from evaluation, and tuning the evaluator to be skeptical, turns out to be far more tractable than making a generator critical of its own work. In APEX, this structural separation is formalized. QA Operational configures the skeptical evaluator. QA Strategic defines the criteria it evaluates against. The generator never grades its own homework.
The two-level QA structure makes this work. QA Strategic defines the criteria. QA Operational translates them into checks that agents run on every iteration. When the human verifies the final output, they're checking the things that agents can't: whether the work actually moves the business forward.
Verification as the Human Role
Verification is the single human responsibility during Execution. It deserves specific attention because it's where the biggest mistake happens: treating verification as a generic checkpoint.
In APEX, verification gates map to domain expertise. The person who understands the code reviews the code artifacts. The person who understands the brand reviews the content. The person who understands the regulatory environment reviews compliance. Each quality gate has a specific owner, documented in the Domain Ownership Matrix. This means verification is parallel, not serial. The review bottleneck is typically the single biggest drag on delivery speed, and it exists because organizations default to serial, generalist review. Domain-mapped verification gates fix that.
Verification ends with a binary decision: accepted or not accepted. If not accepted, specific feedback is captured and the work re-enters the loop. The specificity matters. "Doesn't feel right" is not acceptance feedback. "The tone in section three is too formal for our audience" is. By the time work reaches verification, the remaining issues should be strategic, not mechanical.
Chapter 5: The Reflection Phase
The rhythm that keeps the system alive. Without calibration, APEX is a static pipeline. With it, APEX is an evolving system.

The Cadence
Calibration is the bridge between Reflection and the next Strategic phase. The APEX Cycle prescribes that every work cycle ends with three steps: evaluation, reflection, and calibration. Together they close the loop.
Evaluation is where the human evaluates the cycle's output against the original intent. Not a status meeting. The actual output, live. This is the bridge between Execution and Reflection.
Reflection is where both humans and agents analyze what happened. Agents report their APEX Metrics: first-pass acceptance rate, iteration depth, human touch rate. Humans review the data and identify patterns. This is where Operational Tooling earns its place — without dashboards and metrics visualizations, this step degrades into gut feelings. The data needs to be visible to be actionable.
Calibration is where the team implements changes across whichever area needs them. Maybe Business Context needs more detail because agents keep misinterpreting a requirement. Maybe Orchestration Design has a routing bottleneck. Maybe QA Operational needs tighter checks for a specific deliverable type. Maybe Infrastructure needs a harness reassessment because a new model capability changed the tradeoffs. These changes flow into the next Strategic phase, and the next work cycle runs on the evolved system.
A work cycle can be whatever fits your operation: a day, a week, a two-week period, an entire project. What the cadence prescribes is that every work cycle ends with all three steps. Skip them and you get the Set-and-Forget anti-pattern at the system level.
Adoption Sequence
You don't need to build all nine domains at full depth before you start. The adoption sequence depends on what you're doing, and the three-area structure gives you a natural order.
Platform comes first for everyone. You need a stable runtime and a considered harness decision before anything above it matters. Get Infrastructure to a working state, starting with a deliberate harness decision. Stand up basic Operational Tooling early — even a simple dashboard helps. Security and Compliance can start with basic permissions and grow from there.
After Platform, the path diverges.
If your primary work is product development, invest heaviest in the Spec Area first, specifically Spec Engineering and Business Context. Code agents live or die on spec quality. Get your feature briefs, technical documentation, and acceptance criteria right, and the Config Area follows naturally.
If your primary work is content and editorial, invest heaviest in Agent Design and Orchestration Design first. Content operations need the right agents with the right identities because the workflow between research, writing, editing, and publishing is complex and varies by content type. Business Context fills in alongside as you document brand guidelines.
If your primary work is financial analysis or compliance, invest heaviest in Security and Compliance first, then QA Strategic. Permissions, audit trails, and regulatory constraints have to be airtight before agents touch anything sensitive. Quality definitions need to be precise because the cost of errors is high.
Start with Platform and the domains that matter most for your context. Get them working. Add depth to the others as you learn what's needed through calibration. Trying to fully configure all nine before running your first work cycle is its own anti-pattern. Configure enough to start, then let the Reflection data tell you where to invest next.
Chapter 6: The Ten Principles
These principles govern how APEX operates across all three areas. Each one earns its place through practice, not theory.

Principle 1: Harness First. Your runtime choice sets all constraints. A hierarchical multi-agent system has different capabilities, costs, and failure modes than a single autonomous agent. Decide the harness before you configure anything else.
Principle 2: Human in Control of Outcome. Humans own the outcome — not every step, but the result. They design the system, verify the output, and decide what to change. Agents handle the execution and iteration. The human doesn't need to be at the start and the end of every task. They need to be in control of what the system produces.
Principle 3: Quality In = Quality Out. The output of any agentic system is a direct function of what goes in — specs, context, configuration, criteria. Better input produces better output. Vague input produces vague results. This applies across all three areas: Platform, Specs, and Config.
Principle 4: Agents Review Agents First. All work passes through agent-to-agent review before a human sees it. This is how you get speed without sacrificing quality.
Principle 5: Domain-Mapped Ownership. Quality gates map to expertise, not generic reviews. The person who understands the code reviews the code. The person who understands the brand reviews the content. Nine domains across three areas, each with a clear owner.
Principle 6: Iterate Often, Iterate Fast. Agent-to-agent iteration loops compress what used to take days into hours. Use that speed. Don't gate iterations behind human approval when agents can resolve the issues themselves.
Principle 7: Least Privilege. Every agent gets only the access it needs. No more. A content agent doesn't need production database credentials. A code agent doesn't need access to financial records. Security and Compliance enforces this.
Principle 8: Calibrate the System, Not Just the Output. Reflections improve the system itself, not just the current deliverable. If you find yourself fixing the same kind of issue repeatedly, the system needs to change. That change might live in any of the three areas.
Principle 9: Data-Driven Reflections. Agents report metrics. Iteration counts, error rates, review pass rates, time-to-completion. Humans decide based on data, not gut feelings about whether things are "going well." This is where Operational Tooling becomes essential — metrics that aren't visible aren't actionable.
Principle 10: Think Big, Scale Back. Start with the vision of maximum efficiency, the full system running at scale. Then scale back what doesn't work yet. The opposite approach, cautiously adding one AI tool to one workflow, produces a copilot. Not the structural shift. Design the whole system first. Remove what's premature. Keep the architecture.
Chapter 7: APEX Metrics
Principles without measurement are just opinions. These five metrics tell you whether the system is improving or degrading, and they make data-driven Reflections possible.

APEX needs its own equivalent of DORA metrics, a small set of named indicators that cover the full cycle. Without these, data-driven Reflections are impossible. You're just guessing. APEX defines five.
First-Pass Acceptance Rate is the percentage of deliverables accepted at human verification without being sent back for another iteration. This is the clearest signal of spec quality. If the rate is high, your Spec Area is doing its job. If it's low, something upstream is broken: vague specs, missing business context, unclear acceptance criteria. Track this per deliverable type and per verification gate. A high first-pass rate on code but low on content tells you exactly where to invest.
Iteration Depth is the average number of agent-to-agent iterations per task before it reaches human verification. This measures both spec quality and agent capability. The interesting signal is the trend. If iteration depth decreases cycle over cycle, your specs are getting sharper. If it increases, something is drifting. High iteration depth with high first-pass acceptance means agents are catching and fixing issues before humans see them, which is the system working as designed. High iteration depth with low first-pass acceptance means something more fundamental is wrong.
Human Touch Rate is the percentage of tasks that require human intervention during Execution, outside of the designed verification points. Every time a human steps into the agent loop to unblock or clarify something, that's a touch. This should decrease over time. A high touch rate in early cycles is normal. A high touch rate after ten cycles means your Strategic configuration has gaps that calibration isn't closing. The goal isn't zero. The goal is that the touches are intentional, not symptoms of poor system design.
Calibration Impact measures the change in the other metrics from one cycle to the next. It's the meta-metric. It tells you whether Reflections are producing meaningful system improvements or whether you're going through the motions. If Calibration Impact is flat across cycles, the ceremony is happening but the learning isn't.
Cycle Time is the elapsed time from a spec entering the execution loop to verified delivery. This is the end-to-end measure of how fast the system turns intent into output. As the system matures, cycle time compresses — better specs reduce iteration rounds, better agents execute faster, and sharper quality gates speed up verification. Track per deliverable type because a complex feature and a blog post have fundamentally different time profiles. The value of this metric is directional: shrinking cycle time across consecutive work cycles is the clearest signal that the system is maturing as a whole.
Together these five metrics make Reflections concrete. Instead of "things seem better," you say "First-pass acceptance improved from 60% to 78%, iteration depth dropped from 4.2 to 3.1, human touch rate is down to 12%." That's a conversation you can act on.
Chapter 8: Framework Pluggability
APEX wraps around your existing methodology. It doesn't compete with it.

A common question about APEX is whether it replaces existing workflows. It doesn't. APEX is designed to wrap around your existing processes, not replace them.
The Execution phase of the APEX Cycle is workflow-agnostic. Whatever methodology your team already uses for organizing and executing work, that methodology runs inside Execution. The APEX Cycle provides the outer structure: Strategic design feeding into those cycles, verification during Execution, Reflection evolving all three areas between them.
Scrum + APEX. Your work cycles are still time-boxed iterations. APEX adds Strategic configuration feeding into those cycles, verification closing them, and Reflection evolving the system between them. Your Scrum ceremonies still happen inside the APEX Cycle.
Kanban + APEX. Continuous flow is still continuous flow. APEX adds verification checkpoints and reflection cadences. The Kanban board tracks the work. APEX tracks how well the human-agent system is functioning.
SAFe + APEX. The nine domains map naturally to ownership structures within scaled frameworks. Domain owners align with capability teams or value streams. The calibration cadence aligns with inspect-and-adapt events.
Custom workflows. The three areas and the APEX Cycle don't prescribe how you organize individual tasks. They prescribe the relationship between humans and agents.
The practical implication: you don't need organizational buy-in to "switch to APEX." You need buy-in to add Strategic design, verification, and Reflection around whatever you're already doing. APEX wraps around. It doesn't compete.
Chapter 9: Anti-Patterns
Seven common failure modes. Each one has a specific fix.

Anti-Pattern 1: The Everybody Reviews Everything Trap. When every stakeholder reviews every piece of output regardless of expertise, you get inconsistent feedback and slow cycles. The fix is domain-mapped ownership across the nine domains. The person with the right expertise reviews the right thing.
Anti-Pattern 2: The Set-and-Forget System. You configure your agents once and never run Reflections. Requirements drift, agent capabilities change, and the system degrades silently. The fix is running the full APEX Cycle every work period, with Reflection feeding changes into the next Strategic phase. No exceptions.
Anti-Pattern 3: The Promptless Agent. An agent with no context documents, no brand guidelines, no technical constraints. It produces generic output that needs heavy human editing, which defeats the purpose. The fix is investing in Business Context and Spec Engineering during Strategic, and ensuring Agent Design identity files reference those artifacts.
Anti-Pattern 4: The Unlimited Agent. An agent with full access to everything: production systems, financial data, external communications. One hallucination away from a real incident. The fix is least privilege with an explicit Permission Map in Security and Compliance.
Anti-Pattern 5: The Human-in-the-Middle. A human reviewing every single iteration between agents. This kills the speed advantage entirely. You end up with an expensive, slow pipeline where a human is the bottleneck at every step. The fix is letting QA Operational handle agent-to-agent review and only surfacing work to humans for verification when the agent loop completes.
Anti-Pattern 6: The Missing Harness Decision. Choosing a runtime by default or accident rather than deliberately. You end up fighting the constraints of a system that was never designed for your use case. The fix is making the harness decision the first priority within Infrastructure, documented in a Harness Decision Record.
Anti-Pattern 7: The Feeling-Based Reflection. Running Reflections based on how people feel rather than what the data shows. "Things seem fine" is not a calibration signal. The fix is data-driven Reflections where agents report APEX Metrics and humans make decisions based on those metrics.
Chapter 10: Getting Started
APEX is a starting point. Your first configuration won't be your best. That's the whole point of the APEX Cycle.
A note on what APEX requires. It is not a weekend project. The upfront investment in the Spec Area alone is substantial. That work takes real effort, and if you skip it, you're back to the Promptless Agent anti-pattern.
But the return compounds. Every cycle through Strategic → Execution → Reflection produces a system better than the previous one. After five or ten cycles, the difference between a calibrated APEX system and an ad-hoc collection of agents is enormous.
Start with Platform. Get a stable runtime and a documented harness decision. Then build the Spec Area: Business Context, Spec Engineering, QA Strategic. Then configure the Config Area: Agent Design, Orchestration Design, QA Operational. Run a cycle. Measure. Reflect. Calibrate. Run another cycle.
The organizations that figure out how to organize human-agent teams will have a structural advantage that's difficult to replicate. This divide was explored in The AI Automation Divide and it still holds: the gap between organizations that use AI strategically and those that use it tactically will widen every quarter.
In Part 2, I'll walk through a concrete example of APEX applied to product development. Specific artifacts, real configuration decisions, nine domains populated with real content.
Start, measure, calibrate, repeat.